
In the previous post I analyzed Protocol Buffers format, using JSON as baseline. In this post I’m going to analyze FlatBuffers and compare it with previously studied formats.
FlatBuffers was also created within Google in 2014 under Apache 2.0 license. It was developed to meet specific needs within the world of video games and mobile applications, where resources are more constrained.
Like Protocol Buffers, it relies on predefining the data format with similar syntax and generates a human-unreadable binary content. It has support for multiple languages and allows adding and deprecating fields without breaking compatibility.
The main distinction of FlatBuffers is that it implements zero-copy deserialization: it does not need to create objects or reserve new memory areas to parse the information, because it always works with the information in binary within a memory or disk area. The objects that represent the deserialized information do not contain the information, but know how to resolve the value when their get methods are called.
In the specific case of Java, this is not strictly correct, because for Strings you have to instantiate the char[] needed for its internal structure. But it is only necessary if you call the getter of the String type attribute. Only the information that is accessed is deserialized.
IDL and code generation
The file with the schema could be this one:
namespace com.jerolba.xbuffers.flat;
enum OrganizationType : byte { FOO, BAR, BAZ }
table Attribute {
id: string;
quantity: byte;
amount: byte;
size: short;
percent: double;
active: bool;
}
table Organization {
name: string;
category: string;
type: OrganizationType;
country: string;
attributes: [Attribute];
}
table Organizations {
organizations: [Organization];
}
root_type Organizations;
To generate all Java classes you need to install the compiler flatc and execute it with some parameters referencing where the IDL file is located and the target path of the generated files:
flatc -j -o /opt/src/main/java/ /opt/src/main/resources/organizations.fbs
As with Protocol Buffers, I prefer to use directly docker with an image ready to execute the command:
docker run --rm -v $(pwd)/src:/opt/src neomantra/flatbuffers flatc -j -o /opt/src/main/java/ /opt/src/main/resources/organizations.fbs
Serialization
This is the worst part of FlatBuffers: it’s complex and it’s not automatic. The serialization operation requires a manual coding process, where you describe step by step how to fill a binary buffer.
As you add elements of your data structures to the buffer, it returns offsets or pointers, which are the values used as references in the data structures that contain them. All in a recursive way.
If we see the data structure as a tree, we would have to do a postorder traversal.
The process is very fragile and it is very easy to make mistakes, so it will be necessary to cover this part with unit tests.
The code necessary to serialize the information starting from POJOs would look like this:
var organizations = dataFactory.getOrganizations(400_000)
FlatBufferBuilder builder = new FlatBufferBuilder();
int[] orgsArr = new int[organizations.size()];
int contOrgs = 0;
for (Org org : organizations) {
int[] attributes = new int[org.attributes().size()];
int contAttr = 0;
for (Attr attr : org.attributes()) {
int idOffset = builder.createString(attr.id());
attributes[contAttr++] = Attribute.createAttribute(builder, idOffset,
attr.quantity(), attr.amount(), attr.size(), attr.percent(), attr.active());
}
int attrsOffset = Organization.createAttributesVector(builder, attributes);
int nameOffset = builder.createString(org.name());
int categoryOffset = builder.createString(org.category());
byte type = (byte) org.type().ordinal();
int countryOffset = builder.createString(org.country());
orgsArr[contOrgs++] = Organization.createOrganization(builder, nameOffset,
categoryOffset, type, countryOffset, attrsOffset);
}
int organizationsOffset = Organizations.createOrganizationsVector(builder, orgsArr);
int root_table = Organizations.createOrganizations(builder, organizationsOffset);
builder.finish(root_table);
try (var os = new FileOutputStream("/tmp/flatbuffer.json")) {
InputStream sizedInputStream = builder.sizedInputStream();
sizedInputStream.transferTo(os);
}
As you can see, it’s a pretty ugly code, and you can easily make a mistake.
- Serialization time: 5,639 ms
- File size: 1,284 MB
- Compressed file size: 530 MB
- Memory required: internally creates a
ByteBufferthat grows by power of two. To fit the 1.2 GB of data you need to allocate 2 GB of memory, unless you initially set it to 1.2 GB if you know its size beforehand. - Library size (flatbuffers-java-1.12.0.jar): 64 873 bytes
- Size of generated classes: 9 080 bytes
Deserialization
Deserialization is simpler than serialization, and the only difficulty lies in instantiating a ByteBuffer containing the binary serialized information.
Depending on the requirements we can bring all the content into memory or use a memory-mapped file.
Once deserialized (or rather read the file), the objects you use do not actually contain the information, they are simply a proxy that knows how to locate it on demand. Therefore, if some data is not accessed, it is not really deserialized… on the other hand, every time you access the same value, you are deserializing it.
Reading the entire file into memory
If the available memory allows it and you are going to use the data intensively, you are more likely to want to read everything in memory:
try (RandomAccessFile file = new RandomAccessFile("/tmp/organizations.flatbuffers", "r")) {
FileChannel inChannel = file.getChannel();
ByteBuffer buffer = ByteBuffer.allocate((int) inChannel.size());
inChannel.read(buffer);
inChannel.close();
buffer.flip();
Organizations organizations = Organizations.getRootAsOrganizations(buffer);
Organization organization = organizations.organizations(0);
String name = organization.name();
for (int i=0; i < organization.attributesLength(); i++){
String attrId = organization.attributes(i).id();
......
- Deserialization time accessing some attributes: 640 ms
- Deserialization time accessing all attributes: 2,184 ms
- Memory required: loading the entire file into memory, 1,284 MB
Mapping the file into memory
The Java FileChannel system abstracts whether all the information is directly in memory or whether it is read from disk as needed:
try (RandomAccessFile file = new RandomAccessFile("/tmp/organizations.flatbuffers", "r")) {
FileChannel inChannel = file.getChannel();
MappedByteBuffer buffer = inChannel.map(MapMode.READ_ONLY, 0, inChannel.size());
buffer.load();
Organizations organizations = Organizations.getRootAsOrganizations(buffer);
.....
inChannel.close();
}
- Deserialization time accessing some attributes: 306 ms
- Deserialization time accessing all attributes: 2,044 ms
- Memory required: as it only creates file reading objects and temporary buffers, I do not know how to measure it, and I think it can be considered negligible.
I am surprised that using a memory-mapped file takes slightly less time. Probably as I run the benchmark multiple times, the operating system has cached the file in memory. If I were rigorous with the test I should change the process, but it is good enough to get an idea.
Analysis and impressions
| JSON | Protocol Buffers | FlatBuffers | |
|---|---|---|---|
| Serialization time | 11,718 ms | 5,823 ms | 5,639 ms |
| File size | 2,457 MB | 1,044 MB | 1,284 MB |
| GZ file size | 525 MB | 448 MB | 530 MB |
| Memory serializing | N/A | 1.29 GB | 1.3 GB - 2 GB |
| Deserialization time | 20,410 ms | 4,535 ms | 306 - 2,184 ms |
| Memory deserialization | 2,193 MB | 2,710 MB | 0 - 1,284 MB |
| JAR library size | 1,910 KB | 1,636 KB | 64 KB |
| Size of generated classes | N/A | 40 KB | 9 KB |
From the data and from what I have been able to see by playing with the formats, we can conclude:
- FlatBuffers is highly recommended when deserialization time and memory consumption is important. This explains why it is so widely used in the world of video games and mobile applications. Its serialization API is very delicate and prone to errors.
- In FlatBuffers, in an example like mine where there is a lot of data, in the serialization process it is important to configure a buffer size close to the final result, otherwise, the library will have to continuously extend the buffer, spending more memory and time.
- In FlatBuffers, the JAR dependency needed to serialize and deserialize, together with the generated classes, is ridiculously small.
- While in JSON and Protocol Buffers you need to deserialize all the information to access a part of it, in FlatBuffers you can randomly access any element without having to traverse and parse all the information that precedes it.
- Protocol Buffers takes less space than FlatBuffers because the overhead per data structure (message/table) is smaller, and especially because Protocol Buffers serializes scalars with the value that takes the least bytes, compressing the information.
- For scalar values, FlatBuffers does not support null. If a value is not present it takes the default value of the corresponding primitive (0, 0.0, or false). But Strings can be
null. - If you need to represent the
nullvalue for a scalar, you can define a struct:struct NullableInt32 { i:int32 }. This adds more complexity to the serialization code and consumes more bytes. - If you follow the serialization algorithm, all normalized strings (countries and categories) from the original object graph will appear repeated in the serialized file.
Iterating serialization implementation
Implementing the serialization with FlatBuffers is really hard, but on the other hand, if you understand how it works internally, this problem can become a great advantage that works in its favor.
Every time you do something like this:
int idOffset = builder.createString(attr.id());
you are adding to the buffer a character array, and getting a kind of pointer or offset to use in the object that contains it.
If the same String is repeated in a serialization, can I reuse the pointer each time it appears? Yes.
If in a serialization you know that the same String will be repeated multiple times you can reuse its offset without breaking the internal representation of the serialization.
With a small change every time we serialize a String, using a Map<String, Integer> and querying it every time we add a String, we would have something like this:
var organizations = dataFactory.getOrganizations(400_000)
FlatBufferBuilder builder = new FlatBufferBuilder();
Map<String, Integer> strOffsets = new HashMap<>(); //<-- offsets cache
int[] orgsArr = new int[organizations.size()];
int contOrgs = 0;
for (Org org : organizations) {
int[] attributes = new int[org.attributes().size()];
int contAttr = 0;
for (Attr attr : org.attributes()) {
int idOffset = strOffsets.computeIfAbsent(attr.id(), builder::createString); // <--
attributes[contAttr++] = Attribute.createAttribute(builder, idOffset,
attr.quantity(), attr.amount(), attr.size(),
attr.percent(), attr.active());
}
int attrsOffset = Organization.createAttributesVector(builder, attributes);
int nameOffset = strOffsets.computeIfAbsent(org.name(), builder::createString); // <--
int categoryOffset = strOffsets.computeIfAbsent(org.category(), builder::createString); // <--
byte type = (byte) org.type().ordinal();
int countryOffset = strOffsets.computeIfAbsent(org.country(), builder::createString); // <--
orgsArr[contOrgs++] = Organization.createOrganization(builder, nameOffset,
categoryOffset, type, countryOffset, attrsOffset);
}
int organizationsOffset = Organizations.createOrganizationsVector(builder, orgsArr);
int root_table = Organizations.createOrganizations(builder, organizationsOffset);
builder.finish(root_table);
try (var os = new FileOutputStream("/tmp/flatbuffer.json")) {
InputStream sizedInputStream = builder.sizedInputStream();
sizedInputStream.transferTo(os);
}
- Serialization time: 3,803 ms
- File size: 600 MB
- Compressed file size: 414 MB
- Memory needed: to store those 600 MB it will use a
ByteBufferthat will require 1 GB if you do not preconfigure it.
In this synthetic example, the reduction of the file size reaches more than 50%, and despite having to constantly look up a Map, the time it takes to serialize is significantly lower.
Because the format does not change, the deserialization retains the same properties and the read code does not change. If you choose to read the entire file into memory, you will gain the same memory space, while if you read it as a mapped file, the change will not be noticeable except for the lower I/O usage.
If we add this optimization to the comparison table, we have:
| JSON | Protocol Buffers | FlatBuffers | FlatBuffers V2 | |
|---|---|---|---|---|
| Serialization time | 11,718 ms | 5,823 ms | 5,639 ms | 3,803 ms |
| File size | 2,457 MB | 1,044 MB | 1,284 MB | 600 MB |
| GZ file size | 525 MB | 448 MB | 530 MB | 414 MB |
| Memory serializing | N/A | 1.29 GB | 1.3 GB - 2 GB | 0.6 GB - 1 GB |
| Deserialization time | 20,410 ms | 4,535 ms | 306 - 2,184 ms | 202 - 1,876 ms |
| Memory deserialization | 2,193 MB | 2,710 MB | 0 - 1,284 MB | 0 - 600 MB |
What we are actually doing is compressing the information at serialization time, taking advantage of the fact that we have some knowledge about the data. We are creating a compression dictionary manually.
Iterating again the idea
Can this process of String compression or normalization be applied to data structures that you serialize?
What if the tuple of attribute values were repeated between Organizations, can we reuse it? Yes
We can reuse the pointer of a previously serialized tuple to be referenced from the serialization of another organization. We would only need to create a Map where the key is the Attr class and the value is the offset of its first occurrence: Map<Attr, Integer> attrOffsets = new HashMap<>().
The example I have created for this article is synthetic and the values used are random. But in my real case, with data structures similar to the example, data is more repetitive and data reuse is higher.
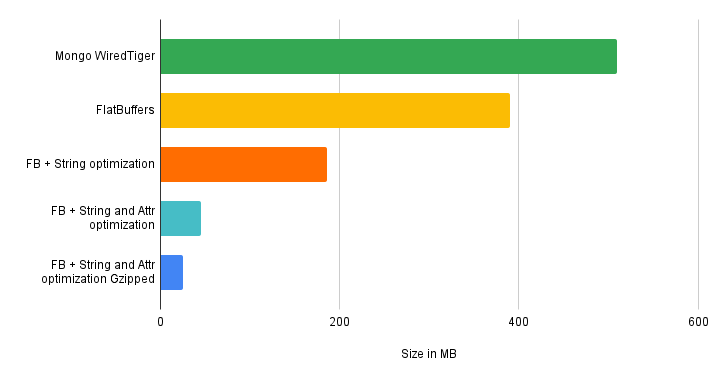
In our real use case, we load the information from a MongoDB collection, and the numbers are these:
- The records in MongoDB occupy 737 MB (which compresses on disk with WiredTiger, taking physically 510 MB)
- If we serialize the same records with FlatBuffers without optimizations, it consumes 390 MB
- If we further optimize by normalizing Strings, it takes 186 MB
- If we normalize the
Attrinstances, the file requires 45 MB - If we compress the file with Gzip, the resulting file is only 25 MB
Conclusion
Knowing how the technologies you use work, their strengths and weaknesses, and the principles they are based on, allows you to optimize their use and push them beyond the usual use cases you are told about.
Knowing how your data looks like is also important when your data volume is high and your resources are limited. How can you structure your data to make it lighter? How can you structure your data to make it faster to process?
In our case, these optimizations have allowed us to postpone a complex architecture change. In an online service, instead of taking 60 seconds to load a batch of information, we can reduce to 3-4 seconds.
If the volume of data becomes really Big Data, I would advise you to use formats where these optimizations are already built-in, such as dictionaries or grouping data into columns.